A Guide to Safely Using Git Delete Branch

Keeping your Git repository clean is a fundamental part of a healthy development workflow, and knowing how to delete branches is your primary tool for the job. The two commands you'll use most are git branch -d <branch-name> for a safe delete of a fully merged branch, and git branch -D <branch-name> to force delete a branch that has unmerged work. This simple cleanup routine stops your repository from becoming a maze of old branches and keeps your team focused on what’s current.
Ready to master Git cleanup? A tidy codebase goes hand-in-hand with smart infrastructure automation. Server Scheduler provides powerful tools to automate your cloud tasks, letting you focus on what really matters. Learn how Server Scheduler can streamline your workflows!
Contents
Ready to Slash Your AWS Costs?
Stop paying for idle resources. Server Scheduler automatically turns off your non-production servers when you're not using them.
Why a Tidy Repository Matters
Maintaining a clean Git repository isn't just about appearances; it’s a crucial discipline for any productive software team. Every time a developer spins up a new branch for a feature, a bug fix, or an experiment, the repository grows. While this branching model is one of Git’s biggest strengths, it can quickly lead to a mess if old, merged, or abandoned branches are left to accumulate. A repository with dozens, or even hundreds, of stale branches can feel like navigating a maze. It makes piecing together the project's history a headache and adds unnecessary cognitive load every time a developer has to find something. Sifting through a sea of outdated branches just to find the right one is a huge waste of time.
This clutter is more than just a minor annoyance—it introduces real risks. A developer might accidentally branch off a stale feature branch, leading to painful merges and wasted effort down the line. It also creates confusion: is feature/user-auth-v2 the latest version, or is it feature/user-auth-final? This kind of ambiguity slows everyone down. Regularly deleting branches is a key part of a healthy development lifecycle. It’s a clear signal that work is complete, merged, and no longer in progress. This simple act of "closing the loop" contributes to a codebase that feels professional and is far easier to maintain.
By diligently cleaning up branches, teams prevent technical debt from piling up in their version control system. A tidy repository is easier to manage, faster to clone, and much simpler for new team members to get up to speed with.
This habit syncs up perfectly with other good organizational practices. For instance, just as a clean repo improves development, effective resource management boosts operational efficiency. To see how these ideas connect, check out our guide on test environment management best practices. For a quick overview of the commands we'll be covering, here’s a handy reference table.
| Command | Action | When to Use It |
|---|---|---|
git branch -d <branch> |
Safely deletes a local branch. | The branch's changes have been fully merged into your current branch. |
git branch -D <branch> |
Force deletes a local branch. | You need to discard unmerged changes and delete the branch anyway. |
git push origin --delete <branch> |
Deletes a remote branch. | The branch is no longer needed on the shared remote repository (origin). |
git fetch --prune or git remote prune origin |
Cleans up stale remote references. | After a remote branch has been deleted, this removes the local tracking branch. |
Deleting Local Branches Safely and Forcefully
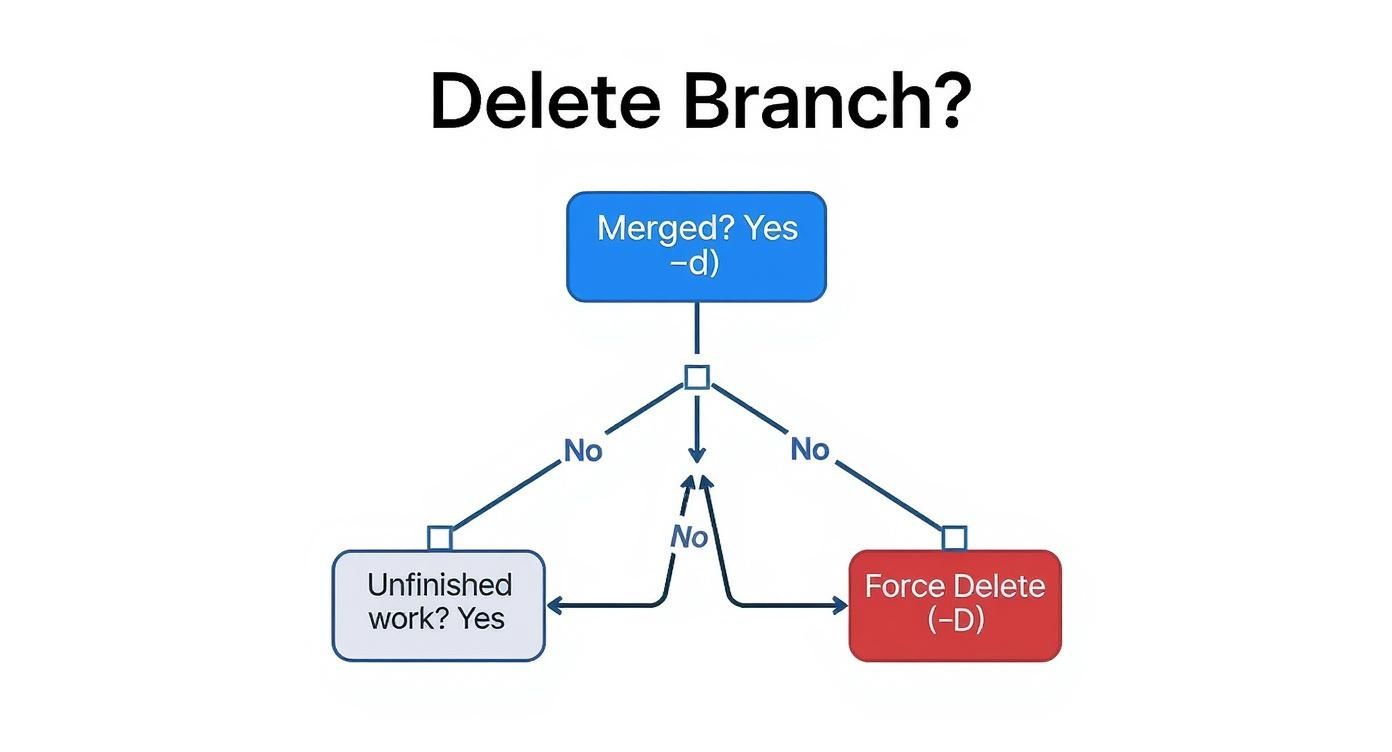
When your local repository starts to feel cluttered with old feature branches, Git gives you two main ways to tidy things up. Knowing the difference between a safe delete and a forceful one is absolutely key to managing your branches effectively and protecting your hard work from being accidentally wiped out. The most common and safest method is using git branch -d <branch-name>. Think of this command as having a built-in safety net. If the branch you're trying to delete has commits that haven't been merged into your current branch (like main), Git will stop you with a helpful error message. This is a lifesaver, preventing you from deleting work that isn't saved anywhere else. It’s the perfect command for routine cleanup after a pull request has been successfully merged.
On the other hand, you have git branch -D <branch-name>—note the capital "D". This is the more powerful, no-questions-asked version. This command will delete the branch you specify regardless of its merge status. It's the right tool for when you're absolutely certain you want to discard a branch and all its history. A common scenario is starting a feature, making a few commits, and then realizing the whole approach is wrong. Instead of merging this flawed work, you just force delete it with git branch -D broken-feature-idea and start fresh.
Pro Tip: The
-Dflag is just an alias for--delete --force. Using it is a clear signal of your intent to discard history, so always double-check which branch you are on and which one you are deleting.
This decision-making process is a frequent activity in development. A 2022 survey revealed that over 78% of professional developers delete branches regularly, with the average developer removing about 15 branches per month. You can explore more about Git branching strategies to see how this fits into the bigger picture.
Removing Branches from Your Remote Repository
Once a pull request gets merged, the feature branch has done its job. But it doesn't just disappear—it usually hangs around on the remote server, whether you're using GitHub, GitLab, or something else. Over time, these old branches create a lot of clutter, making it harder for the whole team to navigate the repository. Cleaning up these obsolete remote branches is a critical piece of repository hygiene. It keeps your shared workspace tidy and professional. A common point of confusion is thinking that git branch -d also removes the branch from the remote server. It doesn't. That command only ever touches your local machine. You need a specific command to tell the remote repository what to do.
The current, recommended way to delete a remote branch is refreshingly clear. It explicitly tells Git that you intend to push a deletion: git push origin --delete <branch-name>. This syntax is preferred because it's so easy to read, leaving no room for costly mistakes. So, after your feature/user-profile branch has been merged, you'd simply run git push origin --delete feature/user-profile to wipe it from the remote. Every now and then, you'll stumble upon an older, more cryptic syntax in legacy scripts or ancient tutorials: git push origin :<branch-name>. This command works by pushing an "empty" reference to the remote branch, which Git interprets as a delete request. While it technically works, the --delete flag is now the standard because its intent is obvious at a glance.
 Automating Cleanup with Remote Pruning
Automating Cleanup with Remote Pruning
Even after you've diligently run git push origin --delete <branch-name>, your local repository hangs onto a ghost of that branch. This is what we call a remote-tracking branch, like origin/feature-xyz, and it doesn't just disappear on its own. Over time, these stale references pile up, cluttering the output of commands like git branch -r and painting a confusing, outdated picture of what’s actually on the remote. The solution to all this local clutter is a Git concept called pruning. Pruning is simply the process of tidying up these obsolete remote-tracking branches, making sure your local repository reflects the true state of the remote. It's an essential bit of housekeeping that keeps your development environment clean and confusion-free.
Think of it like trimming dead branches off a tree to keep it healthy. When a teammate deletes a branch on the remote server, your local Git doesn't automatically get the memo. That origin/feature-xyz reference just sits there, pointing to something that no longer exists. Pruning is your way of telling Git, "Go check the remote server, see which branches are gone, and clean up my local references to them." This action only affects your local repository and is completely safe. For a quick, one-time cleanup, the git fetch --prune command is your best friend. Manually running --prune is great, but you can also automate it with a global configuration setting: git config --global fetch.prune true. This "set it and forget it" strategy is a favorite among seasoned developers because it guarantees your local setup stays perfectly in sync with the remote repository with zero extra effort.
How to Recover a Deleted Branch
We’ve all been there. That heart-sinking moment right after you accidentally delete the wrong branch. Whether you got a little too aggressive with git branch -D or nuked a branch you mistakenly thought was already merged, the good news is your work is rarely gone for good. Git has some powerful safety nets built right in, specifically for moments like these. Your best friend in this situation is git reflog, a command that acts like a detailed diary of everything you've done locally. It keeps a record of almost every change to your repository's HEAD pointer, including commits from branches that no longer exist. This log is the key to turning a potential catastrophe into a minor speed bump.
When you run git reflog, you'll see a list of recent actions. You’re hunting for the very last commit that was at the tip of your deleted branch. The commit message in the description is usually the biggest giveaway. Once you spot the right entry in the reflog, grab the commit hash. Once you have that hash, bringing the branch back from the dead is surprisingly simple. All you have to do is create a new branch that points directly to that lost commit using the command: git checkout -b <new-branch-name> <commit-hash>. This one command instantly creates and switches you to a new branch, effectively putting everything back exactly as it was.
 Team Workflows and Branching Best Practices
Team Workflows and Branching Best Practices
When you're working on a team, effective branch management is less about knowing individual commands and more about everyone agreeing on a consistent strategy. When the whole team follows the same playbook, the repository stays clean, and collaboration just flows better. One of the simplest yet most powerful habits a team can adopt is a standard for naming branches. A good name gives you instant context. For instance, a convention like type/ticket-id/short-description works wonders. A branch named feature/JIRA-123-user-login tells you everything you need to know at a glance.
Here’s another game-changer: adopt a "delete on merge" policy. Modern platforms like GitHub and GitLab have a simple checkbox to automatically delete a branch after its pull request is merged. This one setting prevents feature branches from piling up on the remote server forever. Finally, you absolutely have to guard your most important branches. You can set main and develop as protected branches in your repository settings. This feature stops anyone from accidentally force-pushing over them or deleting them entirely, ensuring your core branches stay stable.
Answering Your Git Branch Deletion Questions
As you get comfortable deleting branches, a few common "what if" scenarios tend to pop up. Technically, you can delete the master or main branch, but you almost never should. Hosting platforms like GitHub and GitLab have branch protection rules for this exact reason, preventing accidental deletion of your most important branches. If you use the force delete command, git branch -D, on a local branch with commits that were never pushed, those commits are in danger of being lost. This is where git reflog becomes your lifesaver, allowing you to find and recover those commits. Lastly, git remote prune is not dangerous at all. It's a safe cleanup command that only removes your local list of remote-tracking branches, not actual branches on the remote server. It simply tidies up your workspace.